Infinipaint: World Modeling a Trivially Simple World
Introduction
I can't fully verbalize why, but there's something so fascinating to me about 'world modeling.'
Generative AI has long focused on training models to create images or videos, but world models invert that emphasis; instead, the goal is to create a neural network with a deep internal understanding of how an environment works. Then, it renders frames as projections of this internal simulation, rather than as arbitrary generations.

Google Deepmind's Genie 3 World Model generating novel worldly scenarios.
More formally, a world model is a neural network that, given a current state and an action, predicts the next state or observation. During training, it learns the latent dynamics of the environment and, at test time, projects this learned structure into images, sensor readings, or video frames. World models are useful when simulating environments too difficult or impractical to build from scratch, everything from CS:GO to the physical world itself.

Alonso et al.'s DIAMOND world model generating frames of CS:GO.

Waymo's Waymo World Model (built on Google DeepMind's Genie 3) generating plausible camera frames and LiDAR responses for real-world driving scenarios.
It’s incredible that entire slices of reality can be compressed into the weights of a neural network. However, this only makes sense for complex, high-entropy domains rich in structure and variation, where the complexity justifies the cost of collecting data, training world models, and running inference at scale. After all, if a world can already be simulated exactly, there's little reason to approximate it with a learned model.
So I wonder, what happens at the other extreme, when you world-model a fully deterministic, fully observable, trivially simple 'world'? In other words: what happens when you world-model something that doesn't really need to be world-modeled?
Problem Definition
Minipaint
Minipaint is a simple 224×224 pixel Pygame-based drawing application with a pen tool, eraser, drawing canvas, brush size slider, and six distinct colors. Every 'variable' (tool state, selected color, canvas contents) is always visible on screen, making Minipaint a fully observable world where any frame action pair contains all context needed to predict the next frame. The only subtle exception is continuous drawing, where strokes are rendered between the cursor’s previous and current positions, creating a single conditional hidden variable.

Minipaint in action: all state variables are visible in the interface, all state changes render deterministically and instantly.
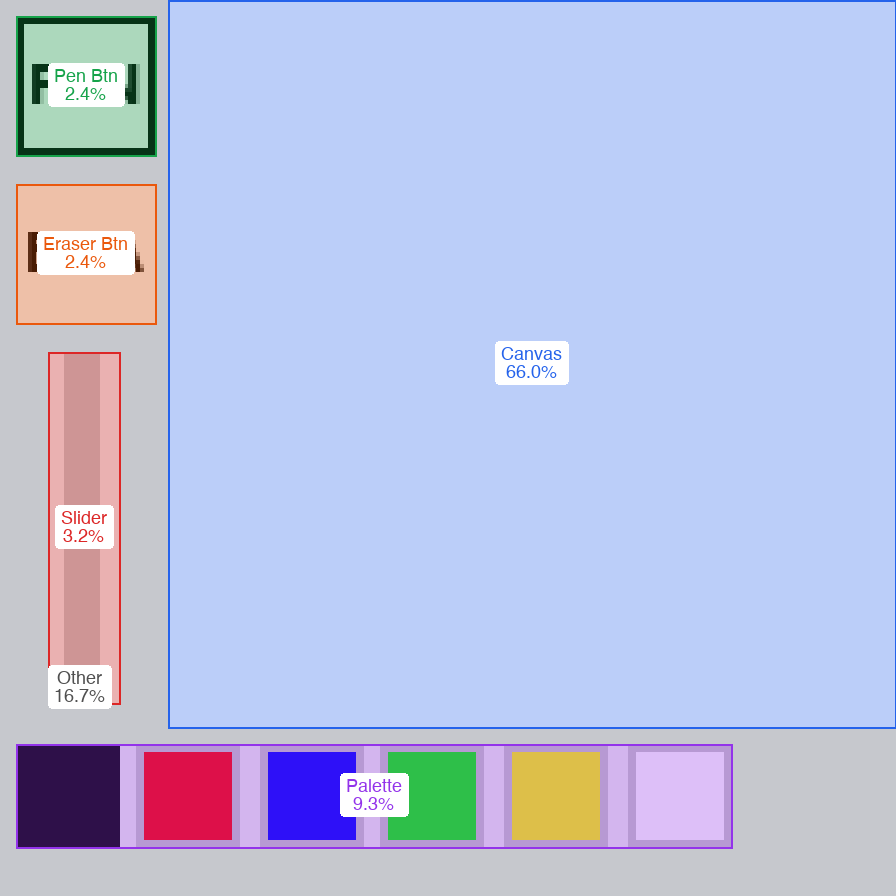
Minipaint's UI layout, with each region's percentage of total screen area labeled.
Our goal is to create Infinipaint, a robust world model of Minipaint that:
- Accurately predicts the correct next frame for any previous frame and input
- Learns visual dynamics without any hardcoded priors/assumptions
- Remains stable over long interactive rollouts
Data Collection
Following NeuralOS, data is stored as frame-action pairs. Each action is applied to Minipaint, and the resulting rendered image is recorded as the corresponding frame. Frames are stored as (56, 56, 3) RGB tensors and actions downsampled to a (56, 56, 2) tensor, where channel 0 is a 2D Gaussian heatmap centered at the cursor and channel 1 is the button state spread across all spatial positions.

A generated episode excerpt: gaussian action heatmap and button state (green = DOWN, red = UP) overlaid on raw canvas frames. Episodes range from 500 to 1000 frames, spanning varying degrees of canvas density.
All training data is synthetically generated by a swarm of procedural agents simulating diverse usage of Minipaint. Agents combine drawing primitives (polylines, arcs, zigzags, spirals, etc.) with random UI interactions to produce action-dense episodes, captured as pixel-accurate Pygame screenshots. Data is generated with fixed random seeds and episodes split via deterministic hash-based partitioning.
Model Architecture
Overview
The Infinipaint world model follows the standard world model framework, and is built from two components:
- A variational autoencoder (VAE) that compresses frames into a compact latent space, discarding redundant pixel-level details.
- A convolutional neural network (CNN) dynamics model that predicts
z_{t+1}fromz_t,a_t, anda_{t+1}.
Once we include both a_t and a_{t+1} Minipaint is effectively deterministic: selected variables are directly observable on each frame, and the second action exposes previous cursor position during continuous drawing. As a result, there's no multimodal next-frame distribution to sample from and no hidden variables/states to keep track of, meaning a non-recurrent stateless CNN is sufficient for next latent prediction.
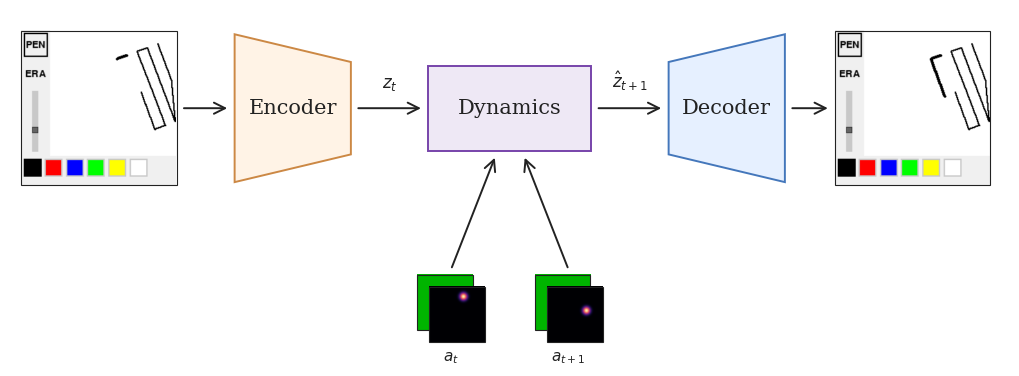
Infinipaint architecture: a VAE compresses frames into latent space, and a non-recurrent stateless CNN predicts the next latent from the current latent and consecutive actions, before decoding back to pixels.
World Encoding (VAE)
Following the NeuralOS and LDM training recipes, the VAE is a convolutional encoder-decoder with channel multipliers [1, 2, 4] over a base of 128 channels with 2 residual blocks per stage. The VAE applies 4× latent compression to 224×224 RGB frames, producing a 56×56×16 latent vector z. Unlike their approaches, however, this work does not use a patch-based adversarial loss or self-attention layers in the decoder.
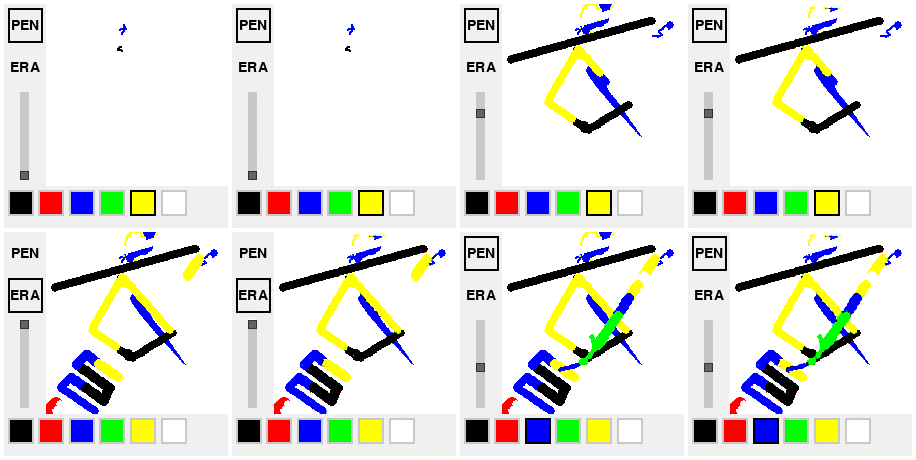
VAE reconstructions at 4× compression.
Early on the VAE excelled at reconstructing the application UI (toolbar, buttons, slider) but struggled with thin brush strokes and color accuracy, especially as the canvas became more crowded. Scaling training data 5×, dropping compression from 8× to 4×, and lowering the LPIPS weight fixed most of this.
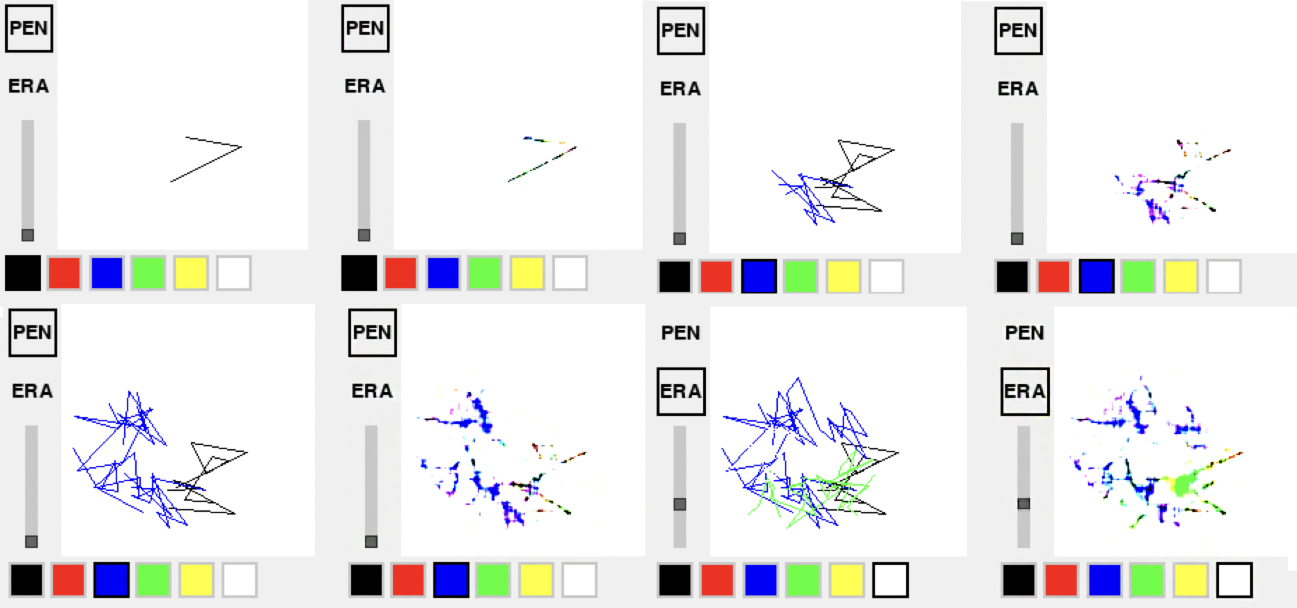
VAE reconstructions at 8× compression.
Latent Space Analysis
To understand what our LatentCNN will need to learn, we can analyze the differences between consecutive frame pairs encoded through our frozen VAE. Two things stand out:
- Latent differences are spatially localized and every channel participates, indicating that our VAE is expressive enough to accurately represent Minipaint's visual dynamics without being overparameterized.
- Latent differences are extremely sparse: even large changes only affect 5–8% of latent positions while typical drawing changes affect less than 1%, indicating that our LatentCNN must be precise enough to modify a small subset of positions while leaving the rest completely untouched.

Latent diffs for a canvas stroke (left) versus a UI interaction (right). Top row: frame pairs, pixel diff, latent magnitude, significance mask. Bottom rows: per-channel diffs across all 16 latent channels.
Predicting Latent Dynamics (LatentCNN)
The LatentCNN is a flat, single-resolution CNN composed of four residual blocks and trained with a delta prediction objective, predicting z_delta = z_next − z_prev rather than z_next directly. The inputs z_prev (56×56×16) and the stacked action tensor [action_prev, action_next] (56×56×4) are each projected to a 56×56×256 hidden representation and summed to produce the initial feature map. Action features modulate every residual block via Spatial Adaptive Group Normalization.
Because latent diffs are so sparse, early iterations collapsed to predicting zero change everywhere. The fix was to compute mean L1 error separately for changed and unchanged regions and average them, so both contribute equally to the loss regardless of how sparse the changes are. Gaussian noise augmentation on z_prev and scheduled sampling are also applied for rollout stability.
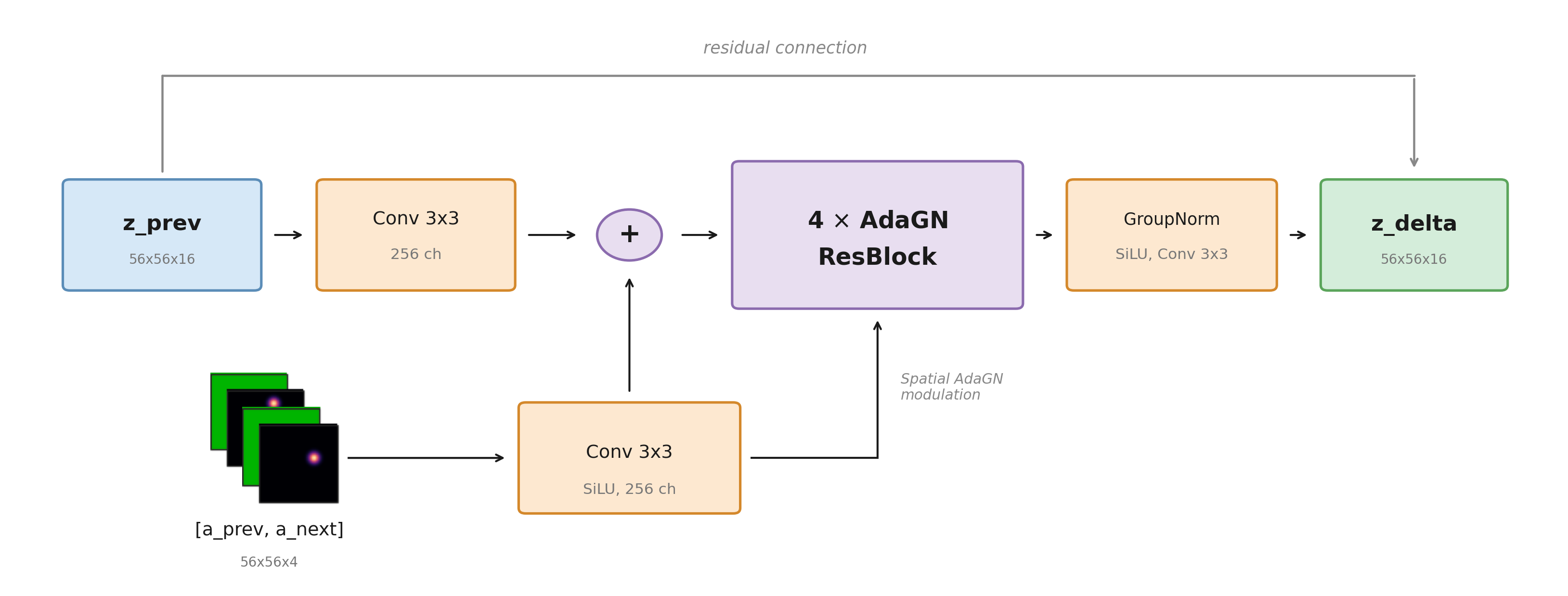
LatentCNN architecture: a flat 56×56 single-resolution CNN predicting sparse latent deltas, with action features injected via Spatial AdaGN at every residual block.
Interactive Viewer
The viewer is a Pygame app that runs the full world model pipeline using MLX or Flax NNX. To avoid compounding roundtrip error, all LatentCNN predictions are applied to a rolling latent state and the VAE only decodes to render the current frame. Diagnostic overlays show an action trajectory heatmap, latent delta magnitude map, and per-block activation norms.
Raw mouse events are too dense for real-time inference, so fixed-interval throttling is used to sample actions every 80 ms (150 steps ≈ 12 sec of continuous pen-down drawing, 500 steps ≈ 40 sec). To maximize useful rollout length, events are only queued for processing if the cursor moves more than 4 pixels, idle frames are only passed into the model to mark the completion of a stroke, and any segments longer than 12 pixels are interpolated into shorter sub-steps. The viewer and inference processes also run on separate threads to keep the interface responsive.
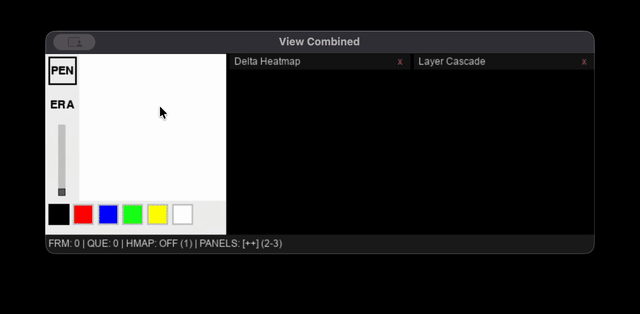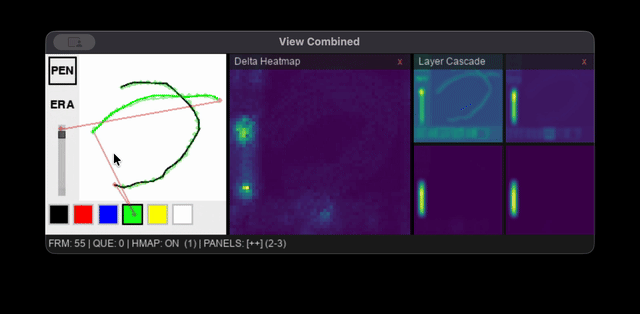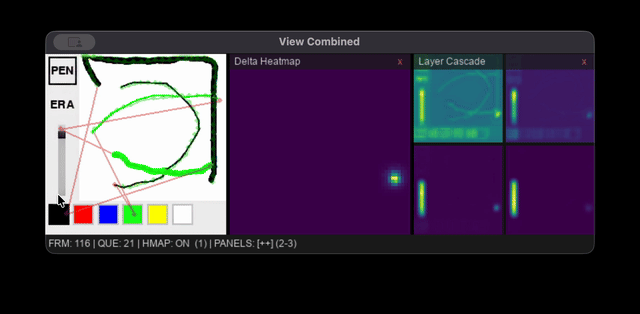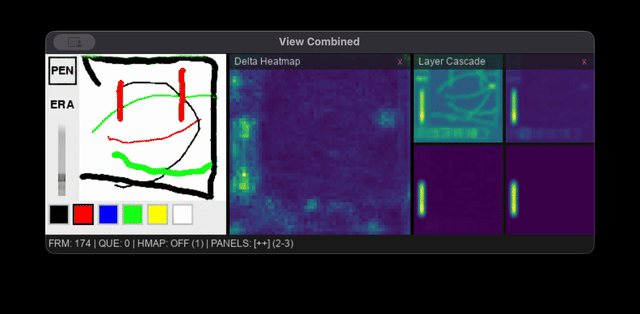
The Infinipaint world model's interactive viewer running the combined world model pipeline on a 2020 M1 Macbook Air's Integrated GPU.
Results / Observations
Overview
Both models were trained separately on a single H100 or H200 spot instance from Prime Intellect, depending on availability. The VAE trained on 237,010 frames across 16 shards while the LatentCNN on 371,799 frame transition pairs across 25 shards. Both runs use bfloat16 and converged without issue.
The complete world model pipeline is evaluated on a held-out test set of 20 episodes (15,609 frame pairs) drawn from 10 data shards. The model runs autoregressively with the rolling latent, same 12px interpolation, and 4px deadzone as the interactive viewer. All metrics are computed between raw ground-truth frames and the VAE-decoded predictions at full 224×224 resolution.
Across evaluation, the world model captures Minipaint's core dynamics on fresh rollouts: tool switching, color selection, drawing, erasing, and brush size adjustment all work as intended. As small per-step errors compound, frames gradually blur and functionality eventually breaks down.
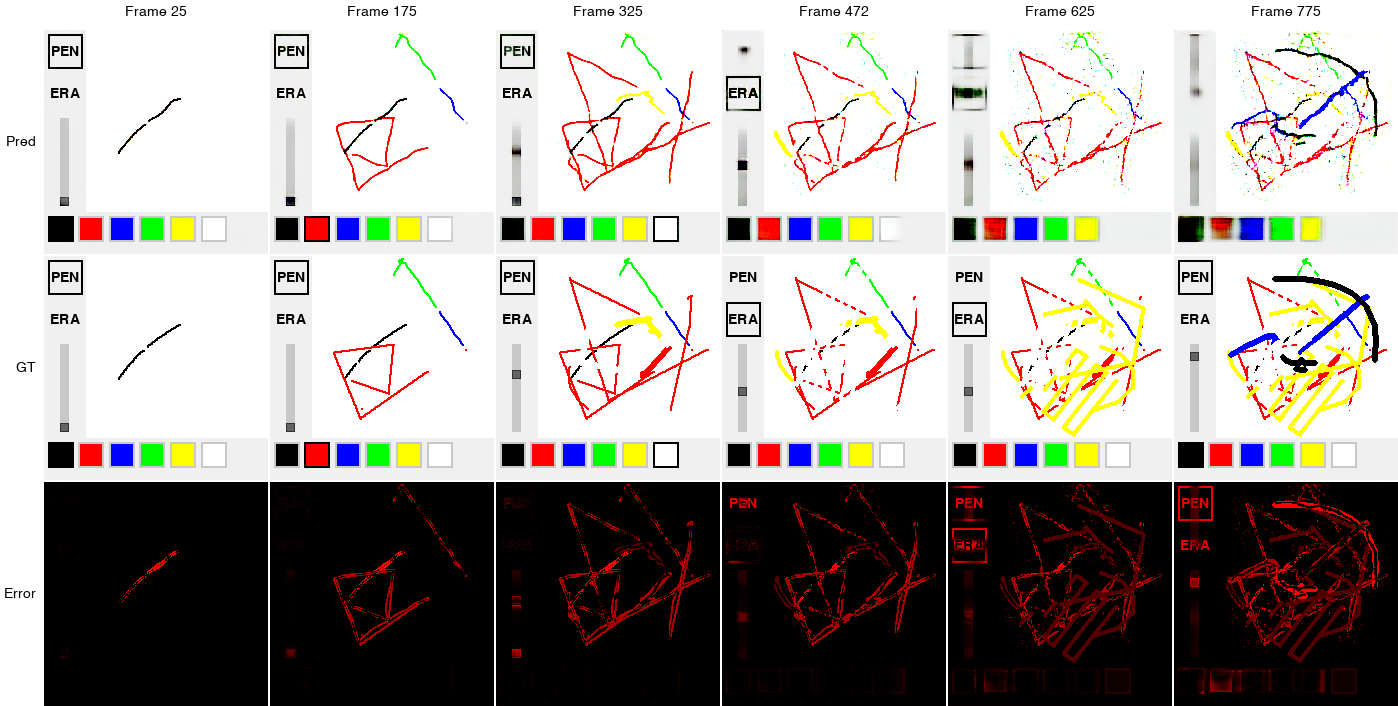
An example autoregressive rollout of the combined VAE-LatentCNN pipeline.
Model Performance
Two metrics are used to track rollout fidelity: SSIM (structural similarity; 0.95+ is near-perfect, 0.80 and lower contains obvious artifacts) and PSNR (pixel-level error in dB, higher is better).
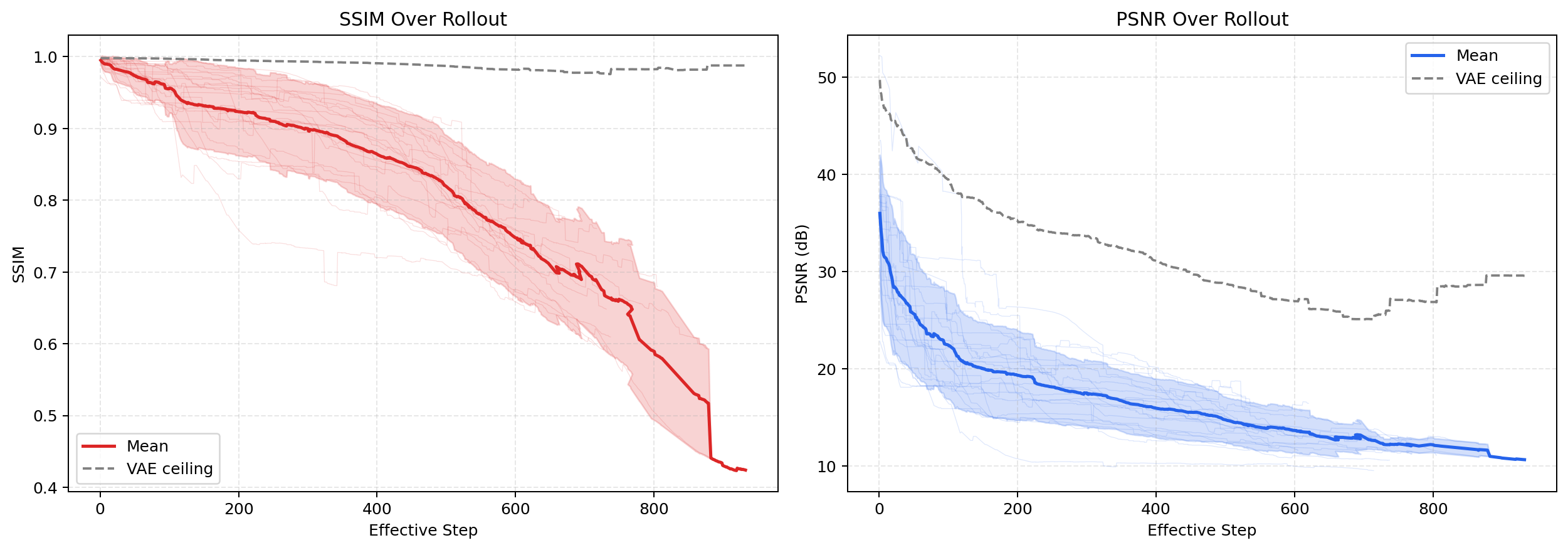
Autoregressive rollout degradation across 20 held-out episodes. Solid lines show mean SSIM and PSNR between ground-truth frames and VAE-decoded predictions at 224×224 resolution, shaded regions indicate episode variance. The dashed reference line marks the VAE reconstruction ceiling, defined as the mean SSIM/PSNR achieved when ground-truth frames are passed through the VAE alone, representing the maximum rollout quality attainable under perfect latent prediction.
Step 1 averages a SSIM of 0.995 (±0.006) and a PSNR of 36.0 dB (±6.0), with quality degrading in roughly three phases:
- Steps 1-150 (stability): SSIM stays above 0.95 (mean ~0.97, PSNR ~25 dB).
- Steps 150-500 (degradation): SSIM drops from ~0.92 to ~0.85 (PSNR ~18 to ~15 dB). Most episodes cross the 0.95 SSIM cliff in this range (mean onset: step 146 ± 94).
- Steps 500+ (collapse): SSIM falls below 0.75 (PSNR ~13 dB), reaching ~0.62 by step 800.
Qualitative Observations
Beyond what aggregate metrics capture, several behavioral patterns stand out:
Functionality persists beyond visual degradation. Discrete UI behaviors degrade more slowly than continuous canvas content: mid-rollout, tool switching remains ~94% accurate (UI region SSIM 0.92) even as the canvas has already fallen to SSIM 0.85. While toolbar geometry drifts and stroke rendering progressively blurs, the underlying discrete UI logic remains mostly intact until late rollout stages.
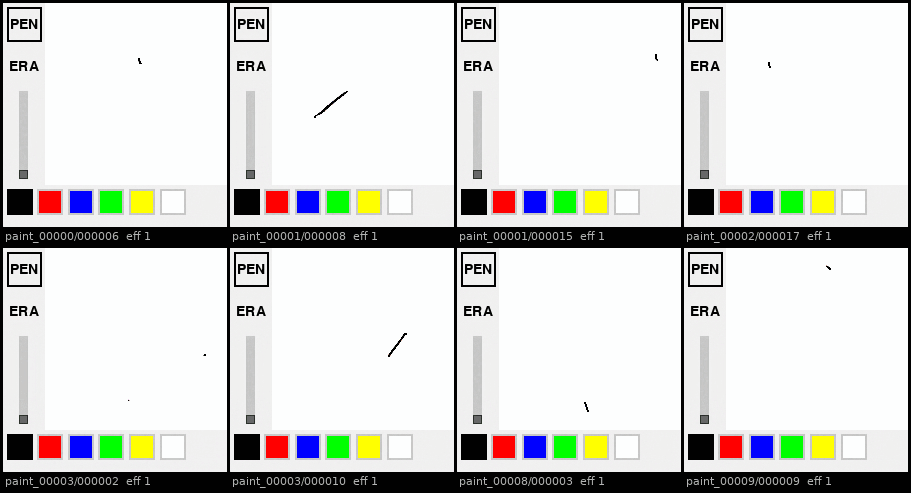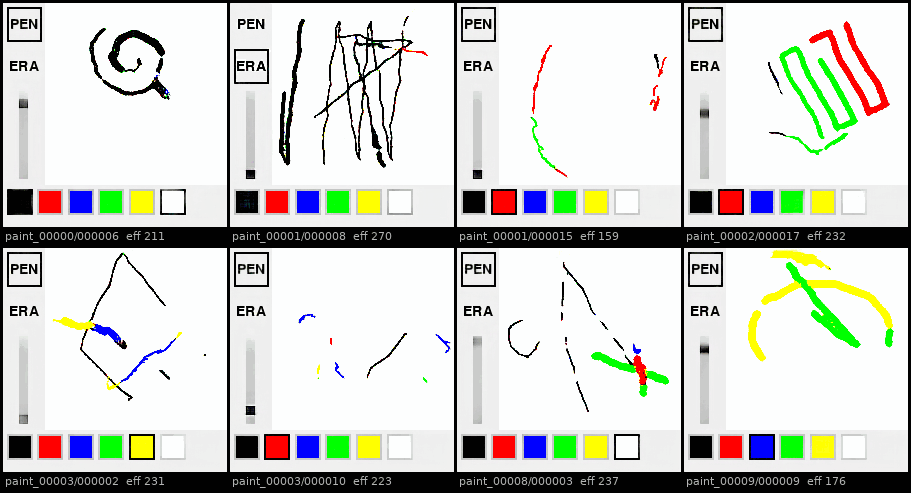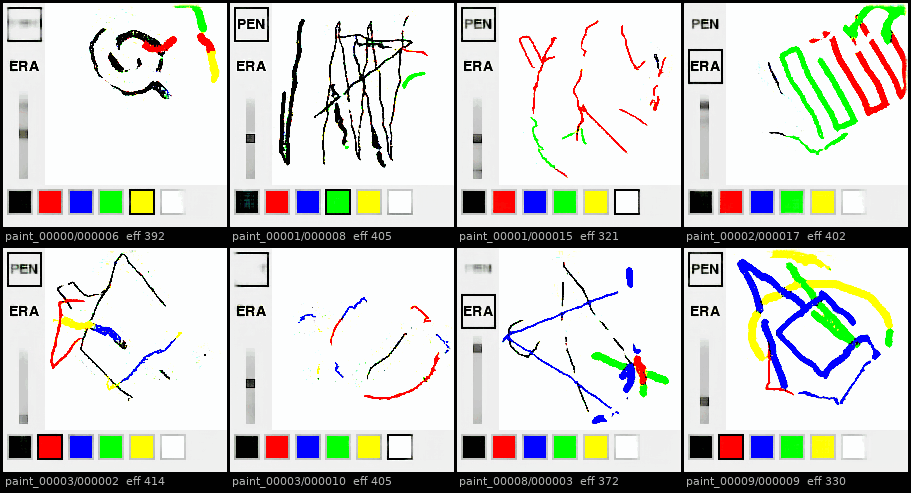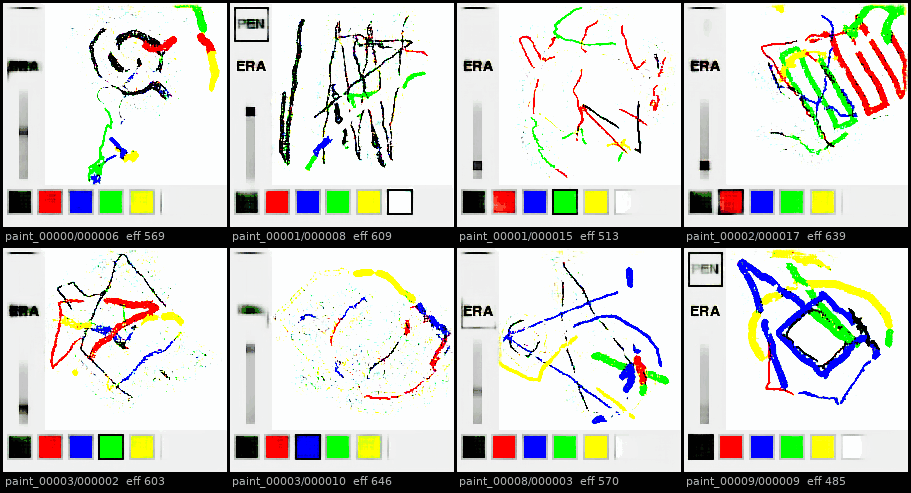
Autoregressive rollouts across 8 held-out episodes: at first UI elements degrade less extremely than the canvas.
Drawing fidelity degrades continuously. Newly drawn stroke quality degrades gradually, with no clean transition point. Early on, straight lines begin to curve slightly, appear thinner, and show subtle color fringing. Later rollouts still place strokes in roughly correct locations, but curvature, thinning, and fringing become increasingly severe.
Erasure is learned approximately. The model correctly lightens pixels where erasure is applied, but pixels are not always reverted to pure white. Furthermore, Eraser L1 improves over the rollout (67.6 early, 59.4 mid, 56.2 late), likely because later erasures act on already-faded pixels already closer to the background color.
Toolbar degradation is abrupt. Discrete elements like button borders and selection highlights resist gradual blurring, but once pixel drift crosses a threshold they break down rapidly. Up to step ~200, the toolbar region loses ~0.00012 SSIM/step, but then begins rapidly deteriorating, losing ~0.00055 SSIM/step.
Tool collapse occurs asymmetrically. Pen-click response accuracy falls from 96.2% (early) to 18.9% (late), while eraser-click response accuracy falls from 100% to 94.7% across the same phases. The model effectively gets stuck in eraser mode: drags tend to fade or erase existing content rather than draw, and 37.6% of late-phase pen strokes produce no visible pixels at all. This failure mode emerges intermittently after 800-1000 frames, usually preceding total state collapse.
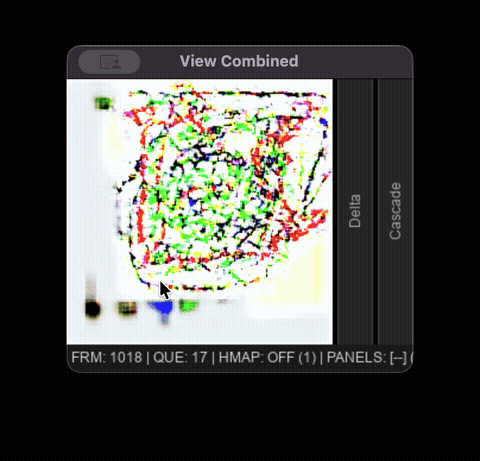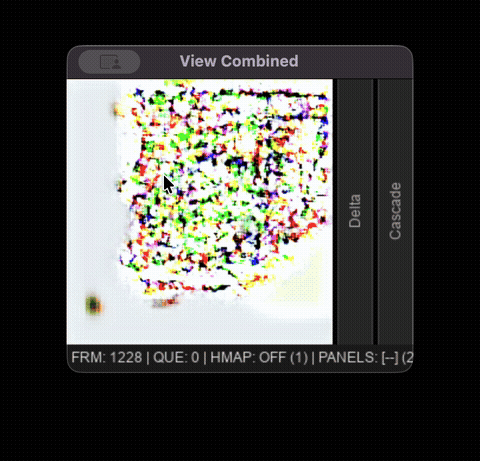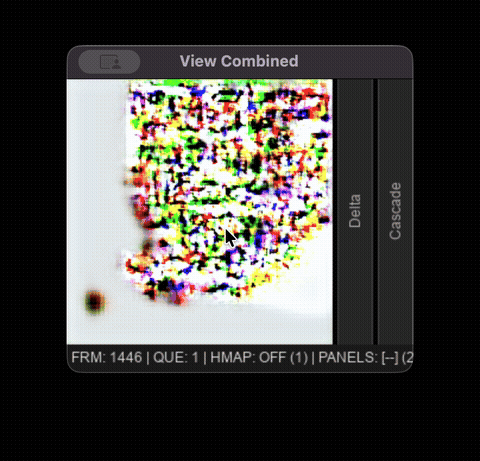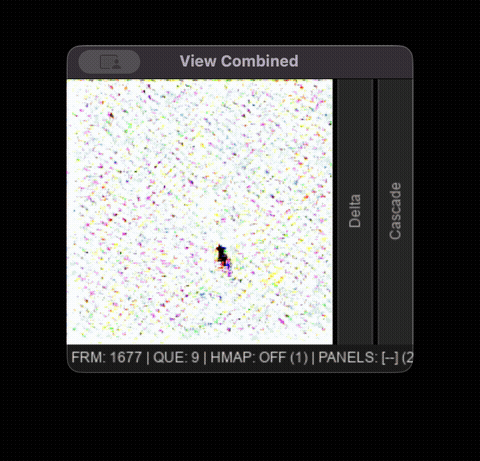
Late phase model degradation displayed in the interactive viewer.
Limitations
Infinipaint has 3 main limitations:
- Because LatentCNN's predictions are slightly imprecise at every step, lines are softened, colors desaturate, and UI elements drift over time. Because predictions are applied autoregressively, the VAE decoder is increasingly asked to reconstruct latents it was never trained on, and in a deterministic system like Minipaint where the ground truth is exact these small errors quickly become obvious.
- VAE reconstruction quality varies across frames: a single frame can decode anywhere from SSIM 0.954 / PSNR 22 dB to SSIM 0.999 / PSNR 52+ dB, depending on canvas density and content.
- Minipaint’s native Pygame implementation renders a step in under a millisecond (0.72 ms on Apple Silicon, 0.63 ms on an H100 host machine). In contrast, the 33.6M-parameter world model requires 202 ms on MLX (280× slower) and 9.16 ms on an Nvidia H100 GPU (14.5× slower) to complete a full forward pass (encode → latent dynamics → decode) at bf16, batch size 1.
Closing Notes
Agentic Research Process
Large parts of this work were carried out with help from Claude Code and Codex. In the last few months, LLMs and agentic programming harnesses have become reliable enough at running scripts and interpreting results that lightweight autonomous research loops are practical. I mainly use agents as experimental assistants to generate visualizations, test hypotheses, and stress-test ideas quickly.
When working with agents, I heavily encourage them to run ephemeral scripts to create visualizations, test hypotheses, and run small experiments. For example, an early LatentCNN wasn't producing any visible changes on the canvas; I instructed Opus 4.6 to run scripts to suggest fixes, and it autonomously discovered the problem (spatial sparsity causing severe underprediction), proposed a fix (reweighted loss), tested it on a smaller-scale training run, and gave me its final analysis and suggestions. Rather than just reading code and speculating, LLMs with strong CLI capabilities can narrow down problems and test solutions, though they often still need to be instructed to use the CLI and provide evidence-based suggestions.
For harder problems or load-bearing code (core data processing/training loop infrastructure, model architectures) I ask agents to propose changes before telling them which options to implement. This extra step helps catch small problematic errors and keeps code quality consistent. For less critical work, I give agents more autonomy and clean up style and formatting afterward.
Conclusion
Returning to the three goals from Problem Definition: Infinipaint predicts next frames accurately, learns dynamics without Minipaint-specific hardcoding, and remains stable through ~150 steps (usable through ~500) before collapsing.
In a complex environment, it's hard to distinguish failures of understanding from failures of rendering. Minipaint is simple enough to isolate the gap: even with a relatively simple architecture and training objective, the model learns the right dynamics, it just can't sustain them indefinitely.
The idea that a neural network can understand the intricacies of an entire 'world' is undoubtedly fascinating, but I've realized an equally important (and far less glamorous) challenge is getting an AI model to render and communicate that understanding back to us—much like we ourselves struggle to render our mental models into words, actions, and art.
Try the model yourself: Source Code